Rose Hendrix
I am a research scientist at the Allen Institute for Artificial Intelligence (AI2) on the Perceptual Reasoning and Interaction (PRIOR) team, where I work on embodied AI in unstructured human environments. Prior to that, I earned my PhD in Mechanical Engineering at the University of Washington, where I was advised by Santosh Devasia and Joseph Garbini. |

|
ResearchI'm interested in how to bring robotics into unstructured human environments, particularly through the use of simulation and synthetic data. Here is my relevant recent work - please see my Google Scholar for a complete history. * denotes equal contribution. |

|
MolmoAct: Action Reasoning Models that can Reason in SpaceJason Lee*, Jiafei Duan*, Haoquan Fang*, ..., Rose Hendrix et al. In submission, 2025 arxiv / website / MolmoAct encodes observations into depth-aware perception tokens, generates spatial plans as trajectory traces, and predicts precise actions, achieving 70.5% on SimplerEnv and 86.6% on LIBERO with explainable and steerable behavior. |

|
GraspMolmo: Generalizable Task-Oriented Grasping via Large-Scale Synthetic Data GenerationAbhay Deshpande, Yuquan Deng, ..., Rose Hendrix et al. CoRL, 2025 arxiv / website / GraspMolmo predicts semantically appropriate, stable grasps from natural language instructions and RGB-D frames. Trained on PRISM, a large-scale synthetic dataset of 379k samples, it achieves 70% success on complex real-world tasks compared to 35% for alternatives, with zero-shot bimanual grasping capabilities. |
|
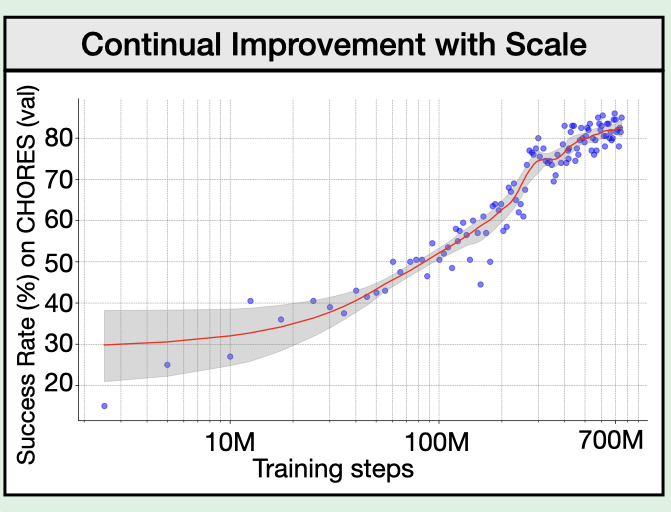
PoliFormer: On-Policy RL with Transformers Results in Masterful NavigatorsKuo-Hao Zeng, Zichen (Charles) Zhang, Kiana Ehsani, Rose Hendrix, Jordi Salvador, Alvaro Herrasti, Ross Girshick, Aniruddha Kembhavi, Luca Weihs CoRL, Outstanding Paper, 2024 arxiv / website / Policy TransFormer (PoliFormer) is a transformer-based policy trained using RL at scale in simulation. PoliFormer achieves SoTA results across LoCoBot and Stretch RE-1, in both simulation and real-world. |

|
Harmonic Mobile ManipulationRuihan Yang, Yejin Kim, Rose Hendrix, Aniruddha Kembhavi, Xiaolong Wang, Kiana Ehsani IROS, Best Paper, Mobile Manipulation, 2024 arxiv / website / HarmonicMM is an end-to-end learning approach that combines navigation and manipulation, significantly improving success rates in complex tasks like door opening and table cleaning, with successful real-world transfer of agents trained in simulation. |
|
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal ModelsMatt Detike, Christopher Clark, ..., Rose Hendrix et al. CVPR, Best Paper Honorable Mention, 2024 arxiv / website / Molmo and PixMo present open weights and open data to advance multimodal AI models, pushing the boundaries of state-of-the-art performance across various tasks. |
|
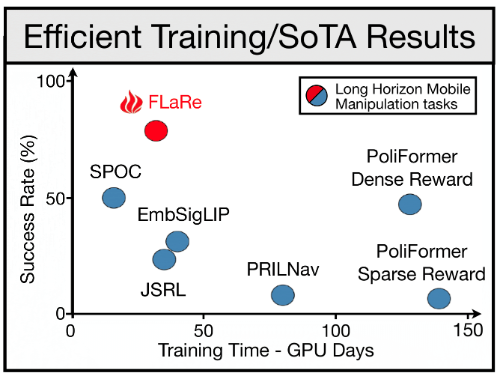
FLaRe: Achieving Masterful and Adaptive Robot Policies with Large-Scale Reinforcement Learning Fine-TuningJiaheng Hu, Rose Hendrix, Ali Farhadi, Ani Kembhavi, Roberto Martin-Martin, Peter Stone, Kuo-Hao Zeng, Kiana Ehsani ICRA, 2024 arxiv / website / FLaRe utilizes large-scale reinforcement learning fine-tuning to create adaptive and highly capable robot policies, achieving state-of-the-art results in both simulated and real-world environments. |
|
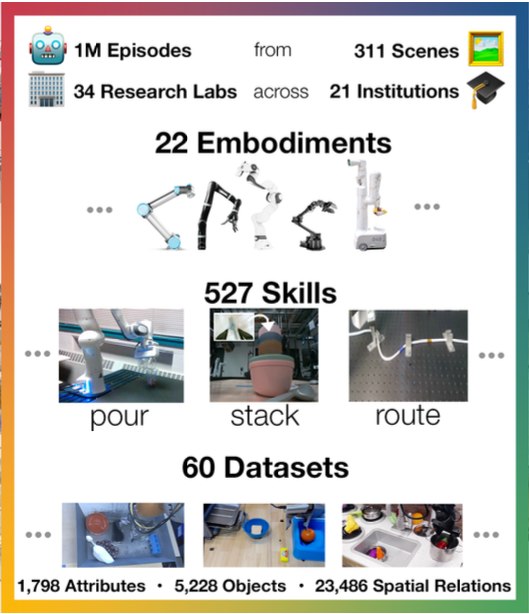
Open X-Embodiment: Robotic Learning Datasets and RT-X Models..., Rose Hendrix, et al. ICRA, Best Paper, 2024 arxiv / website / We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). |

|
SPOC: Imitating Shortest Paths in Simulation Enables Effective Navigation and Manipulation in the Real WorldRose Hendrix*, Kiana Ehsani*, Tanmay Gupta*, Jordi Salvador*, Luca Weihs*, Kuo-Hao Zeng*, Kunal Pratap Singh, Yejin Kim, Winson Han, Alvaro Herrasti, Ranjay Krishna, Dustin Schwenk, Eli VanderBilt, Aniruddha Kembhavi CVPR, 2024 arxiv / code / website / We train a supervised model to imitate shortest path trajectories collected from simulation and show that it generalizes to perform effective navigation and manipulation when deployed on real world agents. |
|
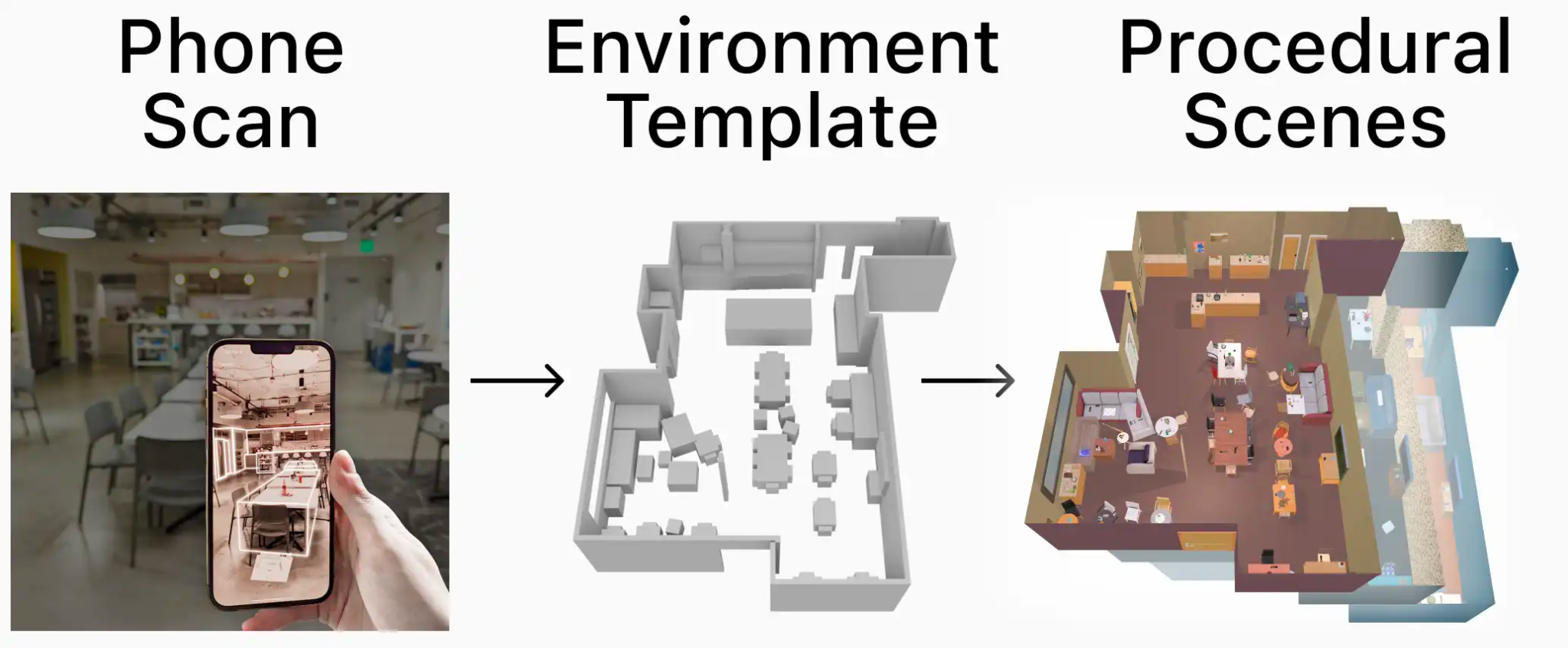
Phone2Proc: Bringing Robust Robots Into Our Chaotic WorldRose Hendrix*, Matt Deitke*, Luca Weihs, Ali Farhadi, Kiana Ehsani, Aniruddha Kembhavi CVPR, 2023 arxiv / code / website / From a 10-minute iPhone scan of any environment, we condition procedural scene generation on that scan to generate training environments. Training a robot to perform ObjectNav in these scenes dramatically improves sim-to-real performance from 35% to 71% and results in an agent that is remarkably robust to human movement, lighting variations, added clutter, and rearranged objects. |
|
Original design and source code from Jon Barron, modified by Leonid Keselman, and email scrambler by Jeff Donohue. |